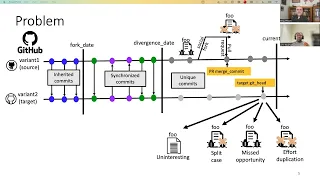
It Will Never Work in Theory
IEEE Software is publishing a short retrospective on this project in 2024. A preprint is available on the magazine's site, or you can download a PDF directly.
@article{nwit2024,
author = {Greg Wilson and Jorge Aranda and Michael Hoye and Brittany Johnson},
title = {It Will Never Work in Theory},
journal = {IEEE Software},
year = {2024},
doi = {10.1109/MS.2024.3362649},
link = {https://www.computer.org/csdl/magazine/so/5555/01/10424425/1Ulj1Qa8tJ6}
}